This is an archived copy of a blog post that I wrote for the Figma company blog. The original blog post can be found here.
We discovered an issue with saving in Figma back in June 2015 that turned out to be the hardest and least-satisfying bug I’ve ever tackled. Fixing it took two whole weeks and all I had to show for it at the end was a single three-line commit! However, the journey to get there led me into the depths of our tech stack and makes for an interesting case study.
It all started when we noticed that our app generated invalid save files every now and then (files that couldn’t be read back in). As with all of our bugs, we first tried to find deterministic steps for reproducing the bug. No one could get it to happen reliably though. Our web app has several sources of non-determinism including asynchronous timers and network events, so this wasn’t too surprising.
The next step was to check the generated files themselves. At the time, our file format was a zip file that wrapped a document encoded using Google’s FlatBuffers library. FlatBuffers is a schema-driven file format with zero-parsing overhead, meaning you can load the raw buffer and traverse the encoded object graph without having to run the parser over the entire file first. The bytes of the generated file looked reasonable but some of the offsets to data later on in the file were suspiciously zeroed out. Data being written out of place is usually a symptom of a memory safety violation, which is when a C++ program reads or writes memory that it shouldn’t (use before initialization, use after free, out of bounds access, etc.).
I have a love-hate relationship with C++, the language that Figma’s editor is written in. There’s a good reason why most graphics software is written in C++: it’s an incredibly practical choice. It lets us rely on important third-party libraries (FreeType, HarfBuzz, Skia, etc.), it contains many low-level language features that have a direct translation to the underlying hardware, existing debugging tools are very mature and sophisticated, and the optimization toolchain contains literally centuries of person-effort. Despite its benefits however, C++ is a perfect storm of poor language design decisions, an error-prone standard library API, and legacy from C which together make it impossible to completely avoid accidentally introducing memory safety violations in large projects.

The C++ language doesn’t have any safeguards against these errors whatsoever, so the C++ community has instead provided tools that attempt to detect these problems. I tried all of the usual tricks without success:
At this point we were getting desperate, but there was one thing left to try to deterministically reproduce the bug: eliminate all sources of non-determinism, create some way of recording user events, and keep recording sessions until the bug happens. Then you have a sequence of events that can be played back in order and the bug should reproduce itself every time. You can even create a reduced test case by randomly dropping events as long as they don’t cause the bug to disappear.
Adding a system like this onto an existing app is a big project because real user sessions have all sorts of events. To limit the scope, we decided to restrict recording to just keyboard and mouse events and use a fuzzer (a program that feeds random inputs to another program) to automatically generate sessions containing only those events instead of trying to record actual users. And it worked! Running the fuzzer for a few days came up with a handful of save failures. Then came the hard part: debugging.
Figma is a web app that runs natively in the browser without plugins. We’re using a compiler called emscripten to compile C++ to JavaScript. This may at first seem impossible since JavaScript is a memory-safe garbage-collected scripting language, but the introduction of WebGL to the web platform accidentally also made it possible to emulate the C memory model directly in JavaScript. WebGL added an API called Typed Arrays to allow JavaScript to efficiently manipulate contiguous arrays of vertex data, but they were so useful that they were broken out into their own specification.
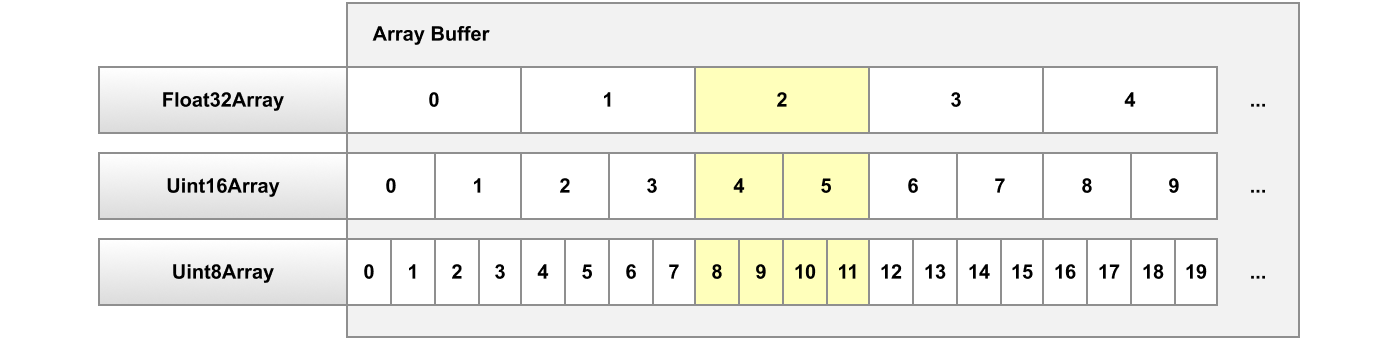
A typed array is an array with a fixed size where all elements must have the same type. For example, every element of a Uint8Array must be an integer from 0 to 255. The critical feature of typed arrays that makes C++ emulation possible is the ability to have multiple typed arrays share the same backing ArrayBuffer. This means the four bytes of element 2 in a Float32Array can be read as elements 8 to 11 of a Uint8Array that shares the same backing store:
When emscripten emulates C++, pointer loads become typed array reads, pointer stores become typed array writes, registers become local variables, and so on. ArrayBuffer sharing means that “casting” between pointers of different types automatically works:

This JavaScript code above probably looks pretty weird. It’s using asm.js, a restrictive subset of JavaScript that’s designed to help the JIT run code as fast as possible.
Things to notice about the code sample shown above:
$value = +$value tells the JIT to assume that $value is a double. Most modern JITs use this information to omit type checks in the generated code.
Stack space is reserved using the “stack pointer” called STACKTOP. Addition is done using a bitwise-or operator because that allows the JIT to use integer wraparound semantics instead of having to generate additional checks and deoptimization points in case the addition overflows outside signed 32-bit range.
Math_imul is a special function created for asm.js that can multiply two 32-bit numbers and return the lower 32-bit half of the 64-bit result (basically mapping to the x86 “imul” instruction). Normal JavaScript multiplication operates on 64-bit doubles, which don’t have enough precision to hold the full 64-bit integer multiplication result.
The loop was unrolled! The emscripten compiler is actually just a backend for LLVM. C++ is still compiled with clang and benefits from almost all of the same optimizations available to native code targets.
Pointers must be divided by the element size, which is why the write to value turns into a write to HEAPF32[$0 >> 2]. A right shift is used instead of a division so the JIT can use a single hardware instruction instead of needing to convert the result to a double and deal with fractional indices returning undefined.
That last point actually turned out to be relevant to this bug. An unaligned load or store is when you try to access memory at an address that’s not divisible by the element size (for example, attempting to load an int from a pointer that’s not a multiple of 4). They are undefined behavior in C++, which means the compiler is allowed to do whatever it wants. Sometimes it just works and sometimes it causes a bus error. In emscripten’s case, the right shift operator effectively rounds the pointer down to the closest valid value, so the load or store is actually done somewhere else!
The emscripten compiler has a debugging option called SAFE_HEAP to instrument your code with checks for this and sure enough, turning it on showed an unaligned store inside the FlatBuffers library. Finally! I filed an issue with the FlatBuffers library and tried everything I could think of to fix it including:
Putting __attribute__((aligned(1))) everywhere. This didn’t work due to LLVM bugs.
Using memcpy everywhere to avoid unaligned loads and stores. This didn’t work because LLVM tries to be clever and change constant-size memcpy calls into aligned loads and stores.
Using a custom memcpy everywhere implemented using the volatile keyword to avoid LLVM optimizations. This didn’t work because FlatBuffers hands out raw pointers, which makes tracking down all access points in existing code very tricky.
I finally gave up and tried fixing the FlatBuffers library itself. This involved digging through emscripten’s extremely verbose generated code and mapping it back to the original C++ code. This can be challenging to say the least, especially when functions have been inlined and nested compound objects have been flattened into array accesses. The problem ended up being in the reallocation code for the main buffer that FlatBuffers grows as it writes out a file. The buffer is filled back-to-front so that the last object written out can be the first object read back in. Attempting to grow the buffer by an odd size caused unaligned accesses for data already in the buffer. The fix was really small: just round the growth amount up to the size of a pointer.

And there you have it! Two weeks, three lines of code.